
티스토리 뷰
Spark에서는 데이터를 분산하고 처리 속도를 높이기 위해 내부적으로 해시를 폭넓게 활용합니다.
해시는 데이터를 균등하게 분산시키고 복잡한 값을 빠르게 비교할 수 있다는 장점이 있습니다.
이번 글에서는 해싱의 기본적인 개념과 Spark에서 사용되는 해시 함수의 작동방식에 대해 살펴보겠습니다.
해싱이란?
해싱(Hashing)은 입력값을 고정된 크기의 출력값(해시값)으로 변환하는 과정을 말합니다.
# Hash Example
"apple" -> 100
"banana" -> 26
"x" -> 1
1225 -> 99
위와 같은 해시함수가 있을 때, "apple"과 "banana"를 직접 비교하는 대신 해시값인 100과 26을 비교함으로써 효율적으로 값을 비교할 수 있습니다.
이처럼 해시는 데이터를 고정된 크기로 압축하여 빠르고 효율적으로 검색/비교/저장하는 데 그 의의가 있습니다.
다만, 해시함수는 큰 입력 공간을 작은 출력 공간으로 매핑하기 때문에 서로 다른 입력이 같은 해시값을 갖는 충돌이 발생할 수 있습니다.
이러한 충돌을 얼마나 잘 방지하느냐가 해시함수의 품질을 평가하는 기준이 되기도 합니다.
그럼에도 충돌을 완전히 막을 수 없기에, 해시값을 저장할 때는 충돌을 처리하는 다양한 기법이 함께 사용되곤 합니다.
암호화 해시 vs 비암호화 해시
해시는 해시값으로부터 원래의 입력값을 유추할 수 있느냐와 같은 보안성을 기준으로 암호화 해시와 비암호화 해시로 구분할 수 있습니다.
암호화 해시는 보안을 목적으로 설계된 해시입니다.
해시값으로 원래의 입력값을 유추한다거나, 같은 해시값을 갖는 다른 입력값을 찾기 어려워야 한다는 보안 요구사항을 만족해야 합니다.
비밀번호와 같이 민감한 정보를 저장하고 비교해야 할 때 사용할 수 있습니다.
SHA256, MD5가 암호화 해시의 대표적인 예시입니다.
비암호화 해시는 보안보다는 성능에 초점을 맞춘 해시입니다.
대량의 데이터를 빠르게 처리하는 것을 목적으로 설계되어 해시 테이블, 데이터베이스 인덱싱 등 다양하게 사용됩니다.
앞으로 살펴볼 해시 함수들도 비암호화 해시의 일종입니다.
Hash Function in Spark
Spark는 Hash Partitioing, Hash Join, Hash Aggregate 등 다양한 상황에서 성능을 높이기 위해 혹은 데이터를 고루 분산하기 위해 해시를 활용합니다.
Spark SQL에서는 SHA, MD5, CRC32, Murmur3, xxHash64와 같은 여러 해시함수를 제공하고 있습니다.
여러 칼럼을 대상으로 해시값을 계산할 수도 있는데, 이때는 내부적으로 해시값이 누적되어 중첩 호출되는 구조로 되어있습니다.
abstract class HashExpression[E] extends Expression {
// ...
override def eval(input: InternalRow = null): Any = {
var hash = seed
var i = 0
val len = children.length
while (i < len) {
hash = computeHash(children(i).eval(input), children(i).dataType, hash)
i += 1
}
hash
}
// ...
}
그래서 여러 칼럼을 해시하는 경우, 칼럼의 순서에 따라서도 해시값이 달라질 수 있다는 점을 유의하면 좋겠습니다.
(Reference)
Murmur3Hash
Spark SQL에서 제공하는 hash() 함수는 내부적으로 Murmur3를 기반으로 32비트 정수값을 반환합니다.
Spark 내부적으로도 HashPartitioning 등 해시를 사용하는 대부분의 경우에 이 해시함수를 사용합니다.
Murmur3는 곱셈과 비트 회전(Rotation)을 조합해서 비슷한 입력값들이 전혀 다른 해시값을 생성(avalanche effect)하도록 설계되었습니다.
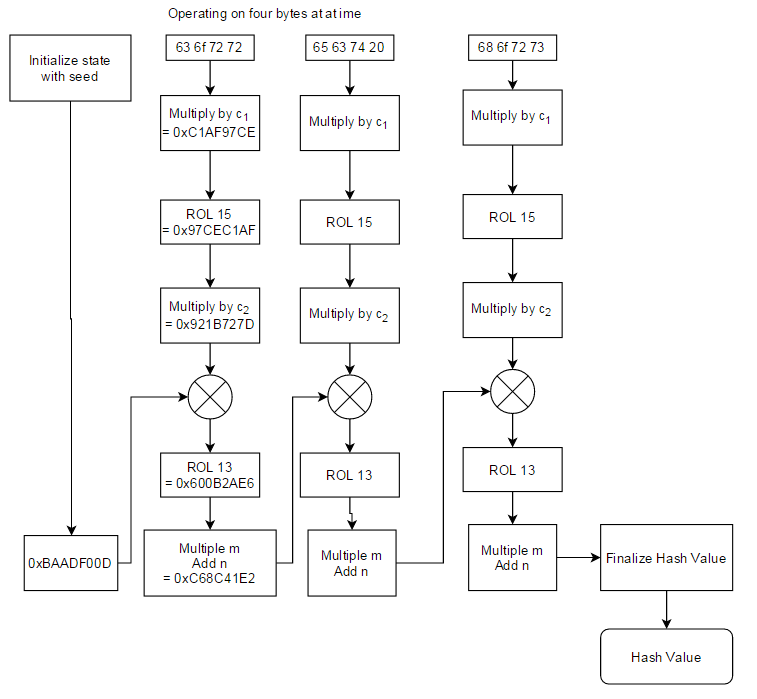
그럼 이제 Spark 내부 코드를 통해 Murmur3 알고리즘을 단계별로 살펴보겠습니다.
1. 입력값을 쪼개고 각각의 조각을 처리 (mixK1)
우선 입력값을 4바이트 단위로 나눕니다.
그 후 각각의 조각에 아래 함수를 적용합니다.
private static final int C1 = 0xcc9e2d51;
private static final int C2 = 0x1b873593;
private static int mixK1(int k1) {
k1 *= C1;
k1 = Integer.rotateLeft(k1, 15);
k1 *= C2;
return k1;
}
각각의 조각들은 mixK1()을 통해 상수 곱셈과 비트 회전을 거쳐 비트들이 섞이도록 합니다.
2. 각 조각들을 하나의 조각으로 결합 (mixH1)
private static int mixH1(int h1, int k1) {
h1 ^= k1;
h1 = Integer.rotateLeft(h1, 13);
h1 = h1 * 5 + 0xe6546b64;
return h1;
}
다음 단계에서는 mixH1()을 통해 각각의 조각을 하나의 조각으로 결합합니다.
비트 조각들은 XOR 연산을 통해 하나로 결합되고 이후 다시 비트 회전과 곱셈을 통해 새로운 값으로 갱신됩니다.
3. 마무리로 다시 한번 섞기 (fmix)
private static int fmix(int h1, int length) {
h1 ^= length;
h1 ^= h1 >>> 16;
h1 *= 0x85ebca6b;
h1 ^= h1 >>> 13;
h1 *= 0xc2b2ae35;
h1 ^= h1 >>> 16;
return h1;
}
마지막으로 fmix()를 통해 최종적으로 비트를 섞습니다.
이 과정에서 XOR, 곱셈, 비트 시프트가 반복적으로 적용되면서 최종 해시값이 입력 비트 전체에 보다 더 민감하게 바뀌도록 처리합니다.
(입력 비트 중 하나만 바뀌더라도 출력 비트의 절반 이상이 변경되도록)
일련의 과정을 그림으로 정리하면 아래와 같습니다.
(Reference)
- https://en.wikipedia.org/wiki/MurmurHash
- https://github.com/apache/spark/blob/master/common/unsafe/src/main/java/org/apache/spark/unsafe/hash/Murmur3_x86_32.java
- https://stackoverflow.com/questions/1057036/please-explain-murmur-hash
xxHash64
Spark는 3.0.0 버전부터 64비트 해시값을 생성하는 xxhash64()를 제공하기 시작했습니다.
더 넓은 해시공간이 필요한 경우 사용할 수 있는데, Spark에서도 내부적으로 HyperLogLog++를 구현하는 데 이를 사용합니다.
(HyperLogLog++는 RDD.countApproxDistinct()와 같이 고유값의 개수를 근사 추정하는 데 사용되는 알고리즘)
놀라운 점은 xxHash64가 Murmur3보다 출력 공간도 넓은데(32비트 -> 64비트) 속도면에서도 더 우수하다는 점입니다.
이는 xxHash가 데이터 처리를 4개의 독립적인 스트림으로 구성하여 CPU의 파이프라인 처리에 최적화된 방식으로 설계되어 있기 때문인데요,
구체적인 구현은 다음과 같습니다.
1. 32바이트 조각을 4등분하여 각각을 처리
우선 전체 입력을 32바이트 조각으로 나눕니다.
이를 다시 4등분(k1 ~ k4)하고, 각 조각에 덧셈, 곱셈, 비트회전 연산을 적용하여 v1~v4를 계산합니다.
do {
long k1 = Platform.getLong(base, offset);
long k2 = Platform.getLong(base, offset + 8);
long k3 = Platform.getLong(base, offset + 16);
long k4 = Platform.getLong(base, offset + 24);
if (isBigEndian) {
k1 = Long.reverseBytes(k1);
k2 = Long.reverseBytes(k2);
k3 = Long.reverseBytes(k3);
k4 = Long.reverseBytes(k4);
}
v1 = Long.rotateLeft(v1 + (k1 * PRIME64_2), 31) * PRIME64_1;
v2 = Long.rotateLeft(v2 + (k2 * PRIME64_2), 31) * PRIME64_1;
v3 = Long.rotateLeft(v3 + (k3 * PRIME64_2), 31) * PRIME64_1;
v4 = Long.rotateLeft(v4 + (k4 * PRIME64_2), 31) * PRIME64_1;
offset += 32L;
} while (offset <= limit);
이 단계의 핵심은 v1 ~ v4의 연산이 독립적기 때문에 CPU 파이프라이닝에 의해 병렬적으로 처리될 가능성이 높다는 것입니다.
이는 Murmur3가 4바이트 단위로 순차적으로 k1, h1 값을 누적 계산하는 것과 대비되는 부분이죠.
2. v1 ~ v4 결합하여 해시값 생성
hash = Long.rotateLeft(v1, 1)
+ Long.rotateLeft(v2, 7)
+ Long.rotateLeft(v3, 12)
+ Long.rotateLeft(v4, 18);
전체 입력에 대해 v1 ~ v4를 계산했다면, 이를 더해서 하나의 값으로 합칩니다.
3. 해시값에 v1 ~ v4를 XOR로 다시 결합
v1 *= PRIME64_2;
v1 = Long.rotateLeft(v1, 31);
v1 *= PRIME64_1;
hash ^= v1;
hash = hash * PRIME64_1 + PRIME64_4;
// v2 ~ v4에서 반복
이후 다시 각 v1 ~ v4에 대해 회전과 곱셈, XOR 연산을 거칩니다.
4. 남은 바이트 처리 + 마무리로 다시한번 섞기
마지막으로 8바이트 미만의 남은 바이트들이 있다면 별도로 처리해주고 fmix()를 통해 최종적으로 전체 비트를 섞습니다.
private static long fmix(long hash) {
hash ^= hash >>> 33;
hash *= PRIME64_2;
hash ^= hash >>> 29;
hash *= PRIME64_3;
hash ^= hash >>> 32;
return hash;
}
fmix에서는 Murmur3와 같이 상수를 곱하고 오른쪽으로 시프트하는 아이디어를 동일하게 사용합니다.
위의 과정을 거쳐 결과적으로 64비트 long 값이 출력됩니다.
(Reference)
- https://xxhash.com/
- https://issues.apache.org/jira/browse/SPARK-13325
- https://github.com/apache/spark/blob/master/sql/catalyst/src/main/java/org/apache/spark/sql/catalyst/expressions/XXH64.java
- https://spark.apache.org/docs/latest/api/python/reference/pyspark.sql/api/pyspark.sql.functions.xxhash64.html
- https://richardstartin.github.io/posts/xxhash
지금까지 Spark에서 사용되는 해시 함수들과 그 내부 구현방식에 대해 살펴봤습니다.
일반적으로는 hash() 함수를 사용하는 것으로도 충분하겠지만 상황에 따라 xxhash64()를 고려해볼 수 있을 것 같습니다.
해시값을 생성 속도가 이후에 해시값을 저장하는 공간 + 해시값을 비교하는 속도보다 더 중요한 경우가 되겠네요.
벤치마크를 보면 입력 길이에 따라서도 결과가 달라질 수 있다고 하니 성능이 중요한 경우 직접 실험해보고 결정하는 것도 좋겠습니다.
'데이터 엔지니어링 > Spark' 카테고리의 다른 글
| [Troubleshoooting] Spark Murmur3 해시의 호환 문제 (1) | 2025.05.17 |
|---|---|
| Spark에서 Auto Increment Key 생성하는 방법 (0) | 2025.04.19 |
| PySpark MySQL 연결하기 (0) | 2024.07.29 |
| PySpark 로컬 환경설정과 S3에서 데이터 읽기 (0) | 2024.07.24 |
- Total
- Today
- Yesterday